ORI or OCI ?
在介绍 ORI 和 OCI 之前先介绍一些专有名词
- Runtime: 负责镜像管理以及 Pod 和容器的真正运行(例如 docker rkt))
- Node: 每个节点都运行一个容器运行时,该运行时负责下载映像并运行容器。
当 Kubelet 想要创建一个容器的步骤
1.Kubelet 通过 CRI 接口(gRPC) 调用 dockershim, 请求创建一个容器. CRI 即容器运行时接口(Container Runtime Interface), 这一步中, Kubelet 可以视作一个简单的 CRI Client, 而 dockershim 就是接收请求的 Server. 目前 dockershim 的代码其实是内嵌在 Kubelet 中的, 所以接收调用的凑巧就是 Kubelet 进程;
2.dockershim 收到请求后, 转化成 Docker Daemon 能听懂的请求, 发到 Docker Daemon 上请求创建一个容器;
3.Docker Daemon 早在 1.12 版本中就已经将针对容器的操作移到另一个守护进程: containerd 中了, 因此 Docker Daemon 仍然不能帮我们创建容器, 而是要请求 containerd 创建一个容器;
4.containerd 收到请求后, 并不会自己直接去操作容器, 而是创建一个叫做 containerd-shim 的进程, 让 containerd-shim 去操作容器. 这是因为容器进程需要一个父进程来做诸如收集状态, 维持 stdin 等 fd 打开等工作. 而假如这个父进程就是 containerd, 那每次 containerd 挂掉或升级, 整个宿主机上所有的容器都得退出了. 而引入了 containerd-shim 就规避了这个问题(containerd 和 shim 并不是父子进程关系);
5.我们知道创建容器需要做一些设置 namespaces 和 cgroups, 挂载 root filesystem 等等操作, 而这些事该怎么做已经有了公开的规范了, 那就是 OCI(Open Container Initiative, 开放容器标准). 它的一个参考实现叫做 runc. 于是, containerd-shim 在这一步需要调用 runc 这个命令行工具, 来启动容器;
6.runc 启动完容器后本身会直接退出, containerd-shim 则会成为容器进程的父进程, 负责收集容器进程的状态, 上报给 containerd, 并在容器中 pid 为 1 的进程退出后接管容器中的子进程进行清理, 确保不会出现僵尸进程;

这个过程乍一看像是在搞我们: Docker Daemon 和 dockershim 看上去就是两个不干活躺在中间划水的啊, Kubelet 为啥不直接调用 containerd 呢?
当然是可以的, 不过咱们先不提那个, 先看看为什么现在的架构如此繁冗.
容器历史小叙
其实 k8s 最开始的 Runtime 架构远没这么复杂: kubelet 想要创建容器直接跟 Docker Daemon 说一声就行, 而那时也不存在 containerd, Docker Daemon 自己调一下 libcontainer 这个库把容器跑起来, 整个过程就搞完了.
而熟悉容器和容器编排历史的读者老爷应该知道, 这之后就是容器圈的一系列政治斗争, 先是大佬们认为运行时标准不能被 Docker 一家公司控制, 于是就撺掇着搞了开放容器标准 OCI. Docker 则把 libcontainer 封装了一下, 变成 runC 捐献出来作为 OCI 的参考实现.
再接下来就是 rkt 想从 docker 那边分一杯羹, 希望 k8s 原生支持 rkt 作为运行时, 而且 PR 还真的合进去了. 维护过一块业务同时接两个需求方的读者老爷应该都知道类似的事情有多坑, k8s 中负责维护 kubelet 的小组 sig-node 也是被狠狠坑了一把.
大家一看这么搞可不行, 今天能有 rkt, 明天就能有更多幺蛾子出来, 这么搞下去我们小组也不用干活了, 整天搞兼容性的 bug 就够呛. 于是乎, k8s 1.5 推出了 CRI 机制, 即容器运行时接口(Container Runtime Interface), k8s 告诉大家, 你们想做 Runtime 可以啊, 我们也资瓷欢迎, 实现这个接口就成, 成功反客为主.
不过 CRI 本身只是 k8s 推的一个标准, 当时的 k8s 尚未达到如今这般武林盟主的地位, 容器运行时当然不能说我跟 k8s 绑死了只提供 CRI 接口, 于是就有了 shim(垫片) 这个说法, 一个 shim 的职责就是作为 Adapter 将各种容器运行时本身的接口适配到 k8s 的 CRI 接口上.
接下来就是 Docker 要搞 Swarm 进军 PaaS 市场, 于是做了个架构切分, 把容器操作都移动到一个单独的 Daemon 进程 containerd 中去, 让 Docker Daemon 专门负责上层的封装编排. 可惜 Swarm 在 k8s 面前实在是不够打, 惨败之后 Docker 公司就把 containerd 项目捐给 CNCF 缩回去安心搞 Docker 企业版了.
最后就是我们在上一张图里看到的这一坨东西了, 尽管现在已经有 CRI-O, containerd-plugin 这样更精简轻量的 Runtime 架构, dockershim 这一套作为经受了最多生产环境考验的方案, 迄今为止仍是 k8s 默认的 runtime 实现.
了解这些具体的架构有时能在 debug 时候帮我们一些忙, 但更重要的是它们能作为一个例子, 帮助我们更好地理解整个 k8s runtime 背后的设计逻辑, 我们这就言归正传.
OCI 以及 CRI 是什么?
OCI,也就是”开放容器标准”其实就是一坨文档, 其中主要规定了两点:
1.容器镜像要长啥样, 即 ImageSpec. 里面的大致规定就是你这个东西需要是一个压缩了的文件夹, 文件夹里以 xxx 结构放 xxx 文件;
容器要需要能接收哪些指令, 这些指令的行为是什么, 即 RuntimeSpec. 这里面的大致内容就是”容器”要能够执行 “create”, “start”, “stop”, “delete” 这些命令, 并且行为要规范.
是给容器运行时用的规范
而 CRI 更简单, 单纯是一组 gRPC 接口, 扫一眼 kubelet/apis/cri/services.go 就能归纳出几套核心接口:
一套针对容器操作的接口, 包括创建,启停容器等等;
一套针对镜像操作的接口, 包括拉取镜像删除镜像等;
还有一套针对 PodSandbox (容器沙箱环境) 的操作接口;
是给 kubelet 用的兼容层接口
containerd 中的 ori 以及 oci 的应用
containerd 1.0 中, 对 CRI 的适配通过一个单独的进程 CRI-containerd 来完成:

containerd 1.1 中做的又更漂亮一点, 砍掉了 CRI-containerd 这个进程, 直接把适配逻辑作为插件放进了 containerd 主进程中:
但在 containerd 做这些事情之情, 社区就已经有了一个更为专注的 cri-runtime: CRI-O, 它非常纯粹, 就是兼容 CRI 和 OCI, 做一个 k8s 专用的运行时: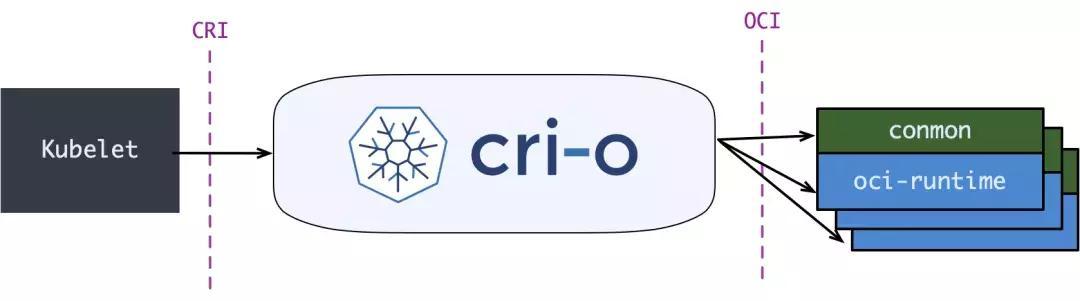
注 : podman 就是基于 OCI-O 开发
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!