k8s v1.17 新特性预告: 拓扑感知服务路由
转摘自roc https://imroc.io
名词解释
- 拓扑域: 表示在集群中的某一类 “地方”,比如某节点、某机架、某可用区或某地域等,这些都可以作为某种拓扑域。
- endpoint: k8s 某个服务的某个 ip+port,通常是 pod 的 ip+port。
- service: k8s 的 service 资源(服务),关联一组 endpoint ,访问 service 会被转发到关联的某个 endpoint 上。
背景
拓扑感知服务路由,此特性最初由杜军大佬提出并设计。为什么要设计此特性呢?想象一下,k8s 集群节点分布在不同的地方,service 对应的 endpoints 分布在不同节点,传统转发策略会对所有 endpoint 做负载均衡,通常会等概率转发,当访问 service 时,流量就可能被分散打到这些不同的地方。虽然 service 转发做了负载均衡,但如果 endpoint 距离比较远,流量转发过去网络时延就相对比较高,会影响网络性能,在某些情况下甚至还可能会付出额外的流量费用。要是如能实现 service 就近转发 endpoint,是不是就可以实现降低网络时延,提升网络性能了呢?是的!这也正是该特性所提出的目的和意义。
k8s 亲和性
service 的就近转发实际就是一种网络的亲和性,倾向于转发到离自己比较近的 endpoint。在此特性之前,已经在调度和存储方面有一些亲和性的设计与实现:
- 节点亲和性 (Node Affinity): 让 Pod 被调度到符合一些期望条件的 Node 上,比如限制调度到某一可用区,或者要求节点支持 GPU,这算是调度亲和,调度结果取决于节点属性。
- Pod 亲和性与反亲和性 (Pod Affinity/AntiAffinity): 让一组 Pod 调度到同一拓扑域的节点上,或者打散到不同拓扑域的节点, 这也算是调度亲和,调度结果取决于其它 Pod。
- 数据卷拓扑感知调度 (Volume Topology-aware Scheduling): 让 Pod 只被调度到符合其绑定的存储所在拓扑域的节点上,这算是调度与存储的亲和,调度结果取决于存储的拓扑域。
- 本地数据卷 (Local Persistent Volume): 让 Pod 使用本地数据卷,比如高性能 SSD,在某些需要高 IOPS 低时延的场景很有用,它还会保证 Pod 始终被调度到同一节点,数据就不会不丢失,这也算是调度与存储的亲和,调度结果取决于存储所在节点。
- 数据卷拓扑感知动态创建 (Topology-Aware Volume Dynamic Provisioning): 先调度 Pod,再根据 Pod 所在节点的拓扑域来创建存储,这算是存储与调度的亲和,存储的创建取决于调度的结果。
而 k8s 目前在网络方面还没有亲和性能力,拓扑感知服务路由这个新特性恰好可以补齐这个的空缺,此特性使得 service 可以实现就近转发而不是所有 endpoint 等概率转发。
如何实现
我们知道,service 转发主要是 node 上的 kube-proxy 进程通过 watch apiserver 获取 service 对应的 endpoint,再写入 iptables 或 ipvs 规则来实现的; 对于 headless service,主要是通过 kube-dns 或 coredns 动态解析到不同 endpoint ip 来实现的。实现 service 就近转发的关键点就在于如何将流量转发到跟当前节点在同一拓扑域的 endpoint 上,也就是会进行一次 endpoint 筛选,选出一部分符合当前节点拓扑域的 endpoint 进行转发。
那么如何判断 endpoint 跟当前节点是否在同一拓扑域里呢?只要能获取到 endpoint 的拓扑信息,用它跟当前节点拓扑对比下就可以知道了。那又如何获取 endpoint 的拓扑信息呢?答案是通过 endpoint 所在节点的 label,我们可以使用 node label 来描述拓扑域。
通常在节点初始化的时候,controller-manager 就会为节点打上许多 label,比如 kubernetes.io/hostname 表示节点的 hostname 来区分节点;另外,在云厂商提供的 k8s 服务,或者使用 cloud-controller-manager 的自建集群,通常还会给节点打上 failure-domain.beta.kubernetes.io/zone 和 failure-domain.beta.kubernetes.io/region 以区分节点所在可用区和所在地域,但自 v1.17 开始将会改名成 topology.kubernetes.io/zone 和 topology.kubernetes.io/region,参见 PR #81431。
如何根据 endpoint 查到它所在节点的这些 label 呢?答案是通过 Endpoint Slice,该特性在 v1.16 发布了 alpha,在 v1.17 将会进入 beta,它相当于 Endpoint API 增强版,通过将 endpoint 做数据分片来解决大规模 endpoint 的性能问题,并且可以携带更多的信息,包括 endpoint 所在节点的拓扑信息,拓扑感知服务路由特性会通过 Endpoint Slice 获取这些拓扑信息实现 endpoint 筛选 (过滤出在同一拓扑域的 endpoint),然后再转换为 iptables 或 ipvs 规则写入节点以实现拓扑感知的路由转发。
细心的你可能已经发现,之前每个节点上转发 service 的 iptables/ipvs 规则基本是一样的,但启用了拓扑感知服务路由特性之后,每个节点上的转发规则就可能不一样了,因为不同节点的拓扑信息不一样,导致过滤出的 endpoint 就不一样,也正是因为这样,service 转发变得不再等概率,灵活的就近转发才得以实现。
当前还不支持 headless service 的拓扑路由,计划在 beta 阶段支持。由于 headless service 不是通过 kube-proxy 生成转发规则,而是通过 dns 动态解析实现的,所以需要改 kube-dns/coredns 来支持这个特性。
前提条件
启用当前 alpha 实现的拓扑感知服务路由特性需要满足以下前提条件:
- 集群版本在 v1.17 及其以上。
- Kube-proxy 以 iptables 或 IPVS 模式运行 (alpha 阶段暂时只实现了这两种模式)。
- 启用了 Endpoint Slices (此特性虽然在 v1.17 进入 beta,但没有默认开启)。
如何启用此特性
给所有 k8s 组件打开 ServiceTopology 和 EndpointSlice 这两个 feature:
1 | |
如何使用
在 Service spec 里加上 topologyKeys 字段,表示该 Service 优先顺序选用的拓扑域列表,对应节点标签的 key;当访问此 Service 时,会找是否有 endpoint 有对应 topology key 的拓扑信息并且 value 跟当前节点也一样,如果是,那就选定此 topology key 作为当前转发的拓扑域,并且筛选出其余所有在这个拓扑域的 endpoint 来进行转发;如果没有找到任何 endpoint 在当前 topology key 对应拓扑域,就会尝试第二个 topology key,依此类推;如果遍历完所有 topology key 也没有匹配到 endpoint 就会拒绝转发,就像此 service 没有后端 endpoint 一样。
有一个特殊的 topology key ““,它可以匹配所有 endpoint,如果 topologyKeys 包含了 ``,它必须在列表末尾,通常是在没有匹配到合适的拓扑域来实现就近转发时,就打消就近转发的念头,可以转发到任意 endpoint 上。
当前 topology key 支持以下可能的值(未来会增加更多):
- kubernetes.io/hostname: 节点的 hostname,通常将它放列表中第一个,表示如果本机有 endpoint 就直接转发到本机的 endpoint。
- topology.kubernetes.io/zone: 节点所在的可用区,通常将它放在 kubernetes.io/hostname 后面,表示如果本机没有对应 endpoint,就转发到当前可用区其它节点上的 endpoint(部分云厂商跨可用区通信会收取额外的流量费用)。
- topology.kubernetes.io/region: 表示节点所在的地域,表示转发到当前地域的 endpoint,这个用的应该会比较少,因为通常集群所有节点都只会在同一个地域,如果节点跨地域了,节点之间通信延时将会很高。
- *: 忽略拓扑域,匹配所有 endpoint,相当于一个保底策略,避免丢包,只能放在列表末尾。
除此之外,还有以下约束:
- topologyKeys 与 externalTrafficPolicy=Local 不兼容,是互斥的,如果 externalTrafficPolicy 为 Local,就不能定义 topologyKeys,反之亦然。
- topology key 必须是合法的 label 格式,并且最多定义 16 个 key。
这里给出一个简单的 Service 示例:
1 | |
解释: 当访问 nginx 服务时,首先看本机是否有这个服务的 endpoint,如果有就直接本机路由过去;如果没有,就看是否有 endpoint 位于当前节点所在可用区,如果有,就转发过去,如果还是没有,就转发给任意 endpoint。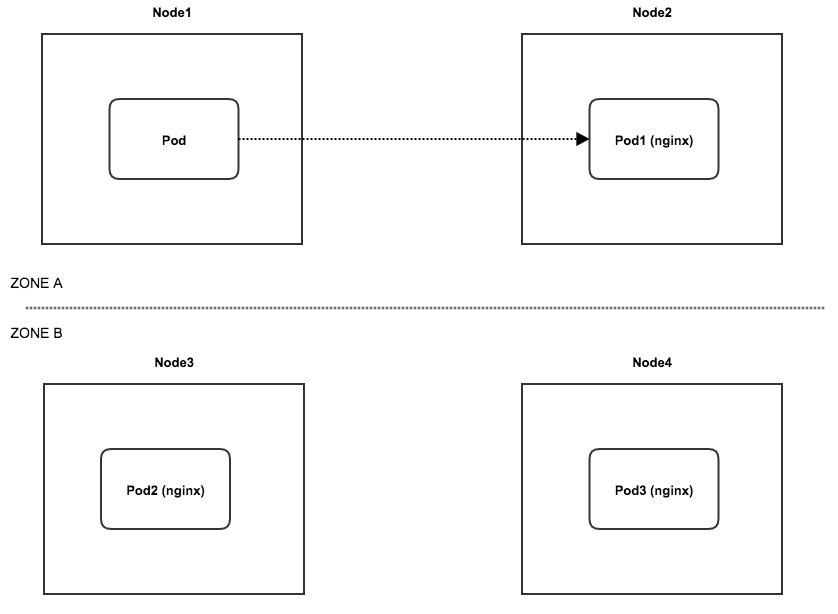
上图就是其中一次转发的例子:Pod 访问 nginx 这个 service 时,发现本机没有 endpoint,就找当前可用区的,找到了就转发过去,也就不会考虑转发给另一可用区的 endpoint。
背后小故事
此特性的 KEP Proposal 最终被认可(合并)时的设计与当前最终的代码实现已经有一些差别,实现方案历经一变再变,但同时也推动了其它特性的发展,我来讲下这其中的故事。
一开始设计是在 alpha 时,让 kube-proxy 直接暴力 watch node,每个节点都有一份全局的 node 的缓存,通过 endpoint 的 nodeName 字段找到对应的 node 缓存,再查 node 包含的 label 就可以知道该 endpoint 的拓扑域了,但在集群节点数量多的情况下,kube-proxy 将会消耗大量资源,不过优点是实现上很简单,可以作为 alpha 阶段的实现,beta 时再从 watch node 切换到 watch 一个新设计的 PodLocator API,作为拓扑信息存储的中介,避免 watch 庞大的 node。
实际上一开始我也是按照 watch node 的方式,花了九牛二虎之力终于实现了这个特性,后来 v1.15 时 k8s 又支持了 metadata-only watch,参见 PR 71548,利用此特性可以仅仅 watch node 的 metadata,而不用 watch 整个 node,可以极大减小传输和缓存的数据量,然后我就将实现切成了 watch node metadata; 即便如此,metadata 还是会更新比较频繁,主要是 resourceVersion 会经常变 (kubelet 经常上报 node 状态),所以虽然 watch node metadata 比 watch node 要好,但也还是可能会造成大量不必要的网络流量,但作为 alpha 实现是可以接受的。
可惜在 v1.16 code freeze 之前没能将此特性合进去,只因有一点小细节还没讨论清楚。 实际在实现 watch node 方案期间,Endpoint Slice 特性就提出来了,在这个特性讨论的阶段,我们就想到了可以利用它来携带拓扑信息,以便让拓扑感知服务路由这个特性后续可以直接利用 Endpoint Slice 来获取拓扑信息,也就可以替代之前设计的 PodLocator API,但由于它还处于很早期阶段,并且代码还未合并进去,所以 alpha 阶段先不考虑 watch Endpint Slice。后来,Endpoint Slice 特性在 v1.16 发布了 alpha。
由于 v1.16 没能将拓扑感知服务路由特性合进去,在 v1.17 周期开始后,有更多时间来讨论小细节,并且 Endpoint Slice 代码已经合并,我就干脆直接又将实现从 watch node metadata 切成了 watch Endpint Slice,在 alpha 阶段就做了打算在 beta 阶段做的事情,终于,此特性实现代码最终合进了主干。
结尾
拓扑感知服务路由可以实现 service 就近转发,减少网络延时,进一步提升 k8s 的网络性能,此特性将于 k8s v1.17 发布 alpha,时间是 12 月上旬,让我们一起期待吧!k8s 网络是块难啃的硬骨头,感兴趣的同学可以看下杜军的新书 《Kubernetes 网络权威指南》,整理巩固一下 k8s 的网络知识。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!