从零到一开发 Operator
转自DaoCloud
1. 前言
在 Kubernetes 已经成为容器调度平台的事实标准之后,对于整个云原生围绕 Kubernetes 来构建自己的业务来说,社区的统一的方案就是通过实现 CRD+Controller 的方式来实现自己的 Kubernetes 的业务能力。此类业务已经覆盖了软件的很多领域,如微服务,DevOps, AI, 安全,网络,存储,大数据,数据库,中间件等等。那接下来,我们就来介绍一下 Operator 是什么,有哪些作用和能力。
Kubernetes 是一个管理容器化应用程序的平台,它会 Watch ETCD 中存储的信息来比较并在必要时协调所表达的期望状态和对象的当前状态,它的这种工作方式我们称为 Reconciliation Loop(协调循环),而协调循环与状态恢复的大部分工作是通过 Controller 实现的。
2. 什么是 Operator
随着 Kubernetes 生态的不断发展,开箱即用的相对底层,通用的 Kubernetes 基础模型元素已经无法支撑不同业务领域下复杂的自动化场景,更高层次对象的出现,带来的是业务运行时繁琐的运维操作以及复杂的部署场景,因此,Kubernetes 社区在 1.7 版本中提出了 Custom Resources And Controllers 的概念,通过自定义资源以及自定义控制器达到对 Kubernetes API 进行拓展的目的,而 Operator 正是这个模型的实现。
CoreOS 在 2016 年底提出了 Operator 的概念,官方定义如下:
An Operator represents human operational knowledge in software, to reliably manage an application. They are methods of packaging, deploying, and managing a Kubernetes application.
简单来说,Operators 就是一组自定义控制器的集合以及由这些控制器管理着的一系列自定义资源,我们将不在关注于 pod,configmap 等基本模型元素,而是将他们聚合为一个应用或服务,Operator 通过控制器的协调循环来使自定义应用达到我们期望的状态,我们只需要关注该应用的期望状态,通过自定义控制器协调循环逻辑,来达到安装,更新,扩展,备份,恢复 7*24 小时不间断的应用或服务的生命周期管理。
3. Operator 的工作原理
Operator 使用自定义资源(CR)管理应用以及其组件的自定义 kubernetes 控制器,自定义资源是 kubernetes 中的 API 扩展,自定义资源配置(CRD)会明确 CR 并列出 Operator 用户可用的所有配置,Operator 监视 CR 类型并且采取特定于应用的操作,确保当前状态与该资源的理想状态相符。
Operator 工作流程: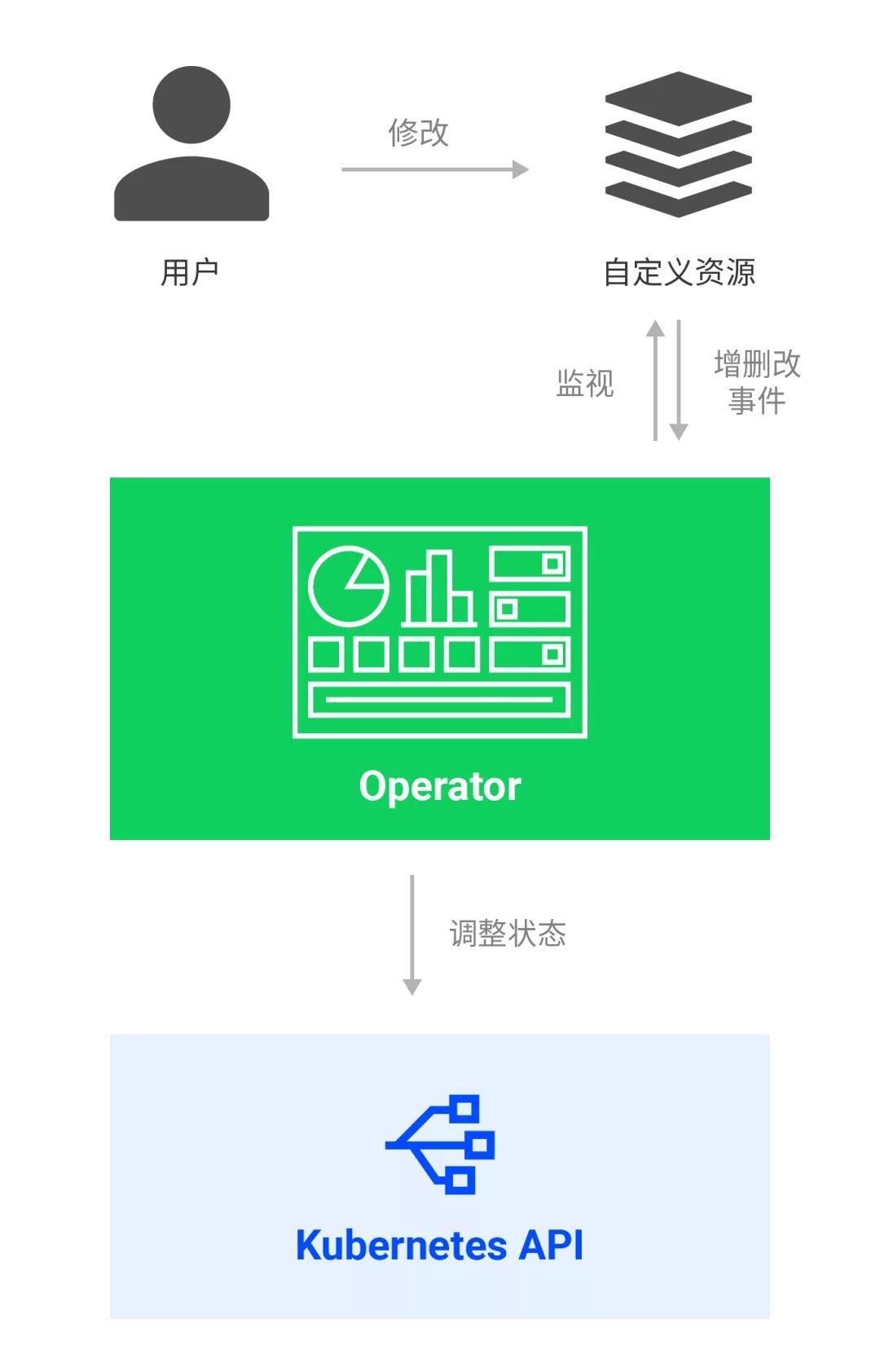
一个 Operator 中主要有以下几种对象:
CRD:自定义资源的定义,Kubernetes API 服务器会为你所指定的每一个 CRD 版本生成 RESTful 的资源路径。一个 CRD 其实就是定义自己应用业务模型的地方,可以根据业务的需求,完全定制自己所需要的资源对象,如 RedisCluster, PrometheusServer 等这些都是可以被 Kubernetes 直接操作和管理的自定义的资源对象。
CR:自定义资源,即 CRD 的一个具体实例,是具体的可管理的 Kubernetes 资源对象,可以对其进行正常的生命周期管理,如创建,删除,修改,查询等,同时 CR 对象一般还会包含运行时的状态,如当前的 CR 的真实的状态是什么,用于观察和判断,CR 对象的真正所处于的状态。
Controller:其实就是控制器真正的用武之地了,它会循环处理工作队列中的动作,按照逻辑协调应用当前状态至期望状态。如观察一个 CR 对象被创建了之后,会根据实现的逻辑来处理 CR,让 CR 对象的状态以及CR对象所负责的业务逻辑慢慢的往最终期望的状态上靠近,最终达到期望的效果,举例来说如果定义了一个 RocketMQ 的 Operator,那在创建 RocketMQCluster 的时候,就会一直协调和观察 RocketMQ 真正的集群是不是创建好了,以及每个节点的状态和可用性是不是健康的,一旦发现不符合期望的状态就会继续协调,就一直保持基于事件的机制,不断检查和协调,去保证期望的状态。
4. 开发一个 Operator
从 0 开始开发一个 Operator 是非常困难的,因此 Operator Framework 为我们提供了 webhook 以及 controller 的框架,使开发者可以忽略一些 Kubernetes 底层细节,只需要关注于被管理应用的运维逻辑实现。
目前主流的 Operator Framework 主要有两个:Kubebuilder 以及 Operator SDK。以下将以 DaoCloud 自研的 RocketMQ Operator 为例,介绍使用 Operator SDK 开发一个 Operator 的过程。
4.1. 创建 rocketmq operator 项目,并生成样板文件
mkdir rocketmq-operator
operator-sdk init –domain daocloud.io
生成以下文件以及目录: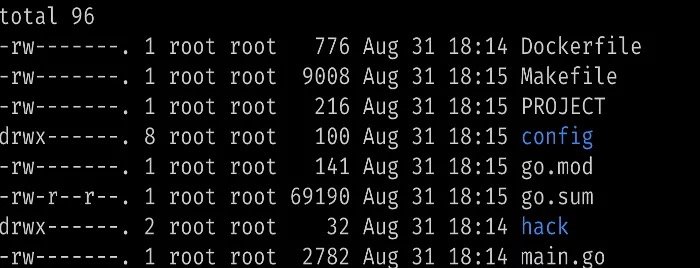
go.mod:与我们的项目匹配的新 Go 模块,具有基本依赖项。
PROJECT:我们应用的一些元数据元数据
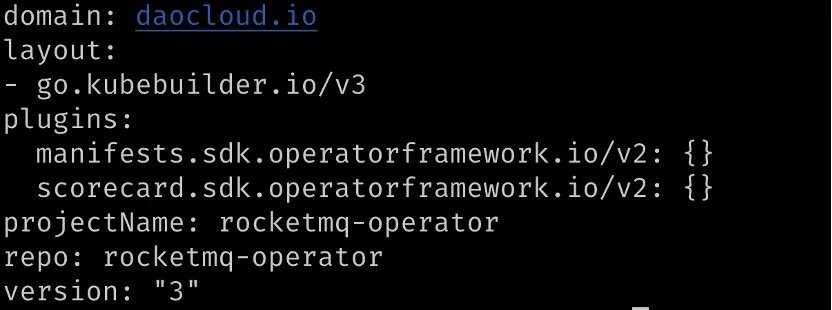
如上,定义了项目名称,版本以及 repo 等
Makefile:构建与部署控制器的工程文件
Config: 部署控制器的一些编排文件,包括控制器,RBAC 等
4.2. 创建组为 rocketmq 版本为 v1 类型为 Broker 的新的自定义资源定义(CRD),并设置控制器
operator-sdk create api –group rocketmq –version v1 –kind Broker –resource –controller
生成文件目录结构如下:
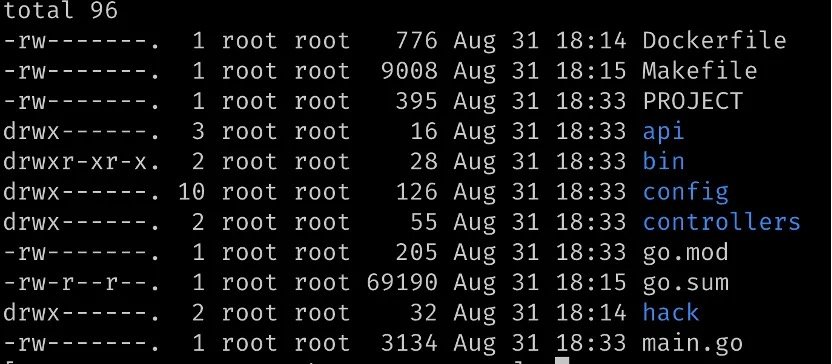
再次查看 PROJECT 文件: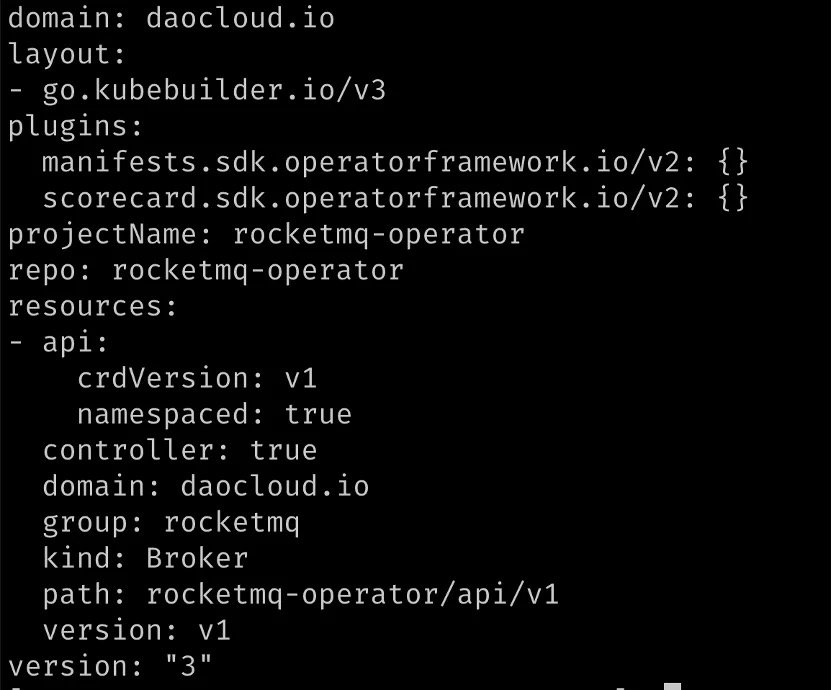
PROJECT 文件中新增了 Resources 字段,描述了我们添加的 Broker CRD 以及它的版本。
Api:自定义类型元数据存放位置,每次创建新类型都会在此处生成新文件。
Controller:自定义资源的控制器协调循环逻辑
4.3. 关注于自定义类型与控制循环
查看 api/v1/ broker_types.go 文件,我们对 BrokerSpec 以及 BrokerStatus 做一些定义,以使 Kubernetes 通过 Controller 协调 Broker

如下所示,我们定义了一系列字段来设置对 Broker 的期望状态,同时也定义了一系列字段来描述 Broker 的当前状态,以供我们很方便的监控 Broker 的生命周期


由上述介绍我们已经知道控制器主要完成协调循环逻辑, 将自定义资源不断推向期望状态,需要注意的是控制器运行在集群上并对集群资源进行增删改查,所以需要 RBAC 权限。
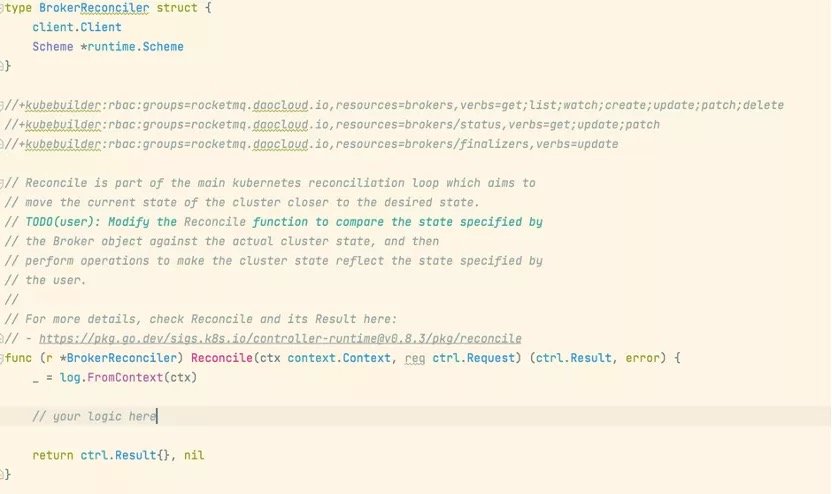
控制器会监视资源的增删改事件,并触发 reconcile 函数作为响应,每个控制器都有两个核心组件:Informer 以及 Workqueue,Informer 负责 Watch 指定资源的变化,将增删改时间发送到 Workqueue 中,然后控制器的 Worker 从Workqueue 中取出事件交由控制器程序处理,这些机制 controller-runtime 包已经帮我们实现,当我们需要设置对指定的资源进行 Watch 时,只需更改 broker_controller.go 中 SetupWithManager 方法即可。
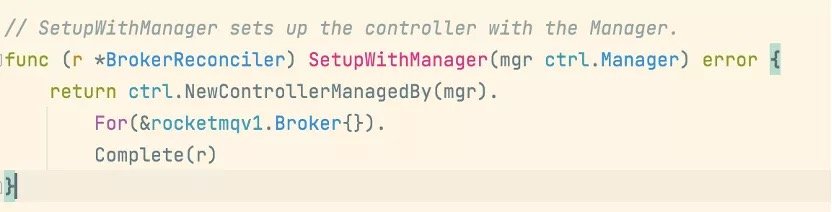
如上,当前控制器会监听 Broker 资源,如果我们希望它同时监听 Deploymeng/Pod 等资源可以用 For 进一步指定,如果我们希望监听由 Broker 类型创建的 Deploymeng,可以使用 Owns 进行指定,当然这要求 Broker 与由他创建的 Deployment 具有从属关系。
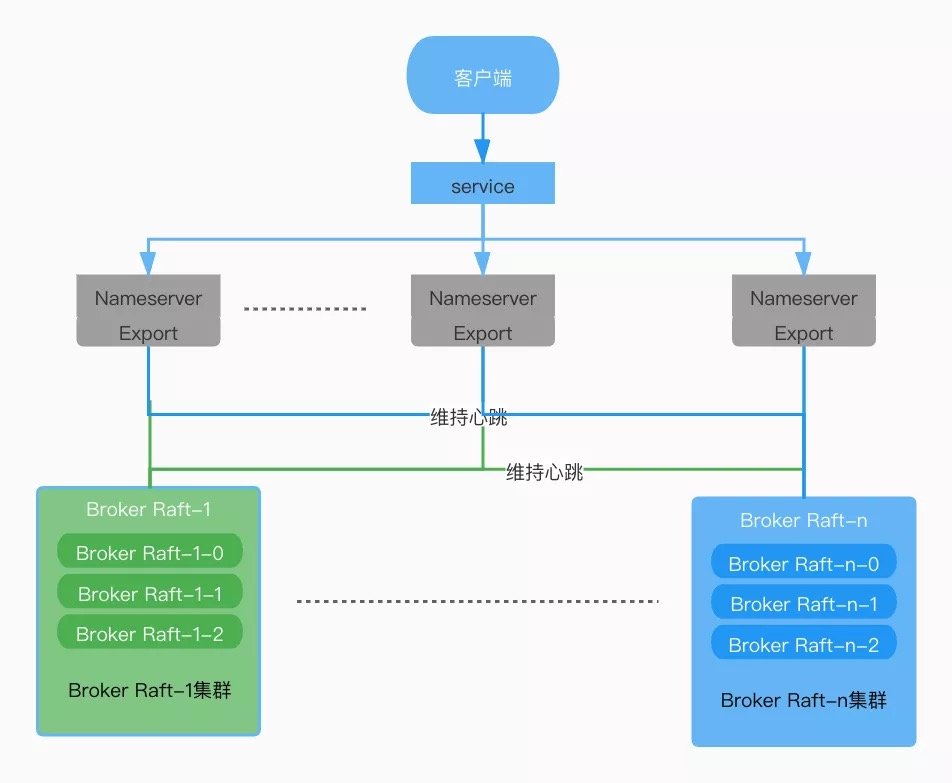
RocketMQ Operator Broker 使用 DLedger 模式部署,实现了按组扩缩容,配置文件热更新,动态获取 Nameserver 地址等功能,简单的协调逻辑如图:
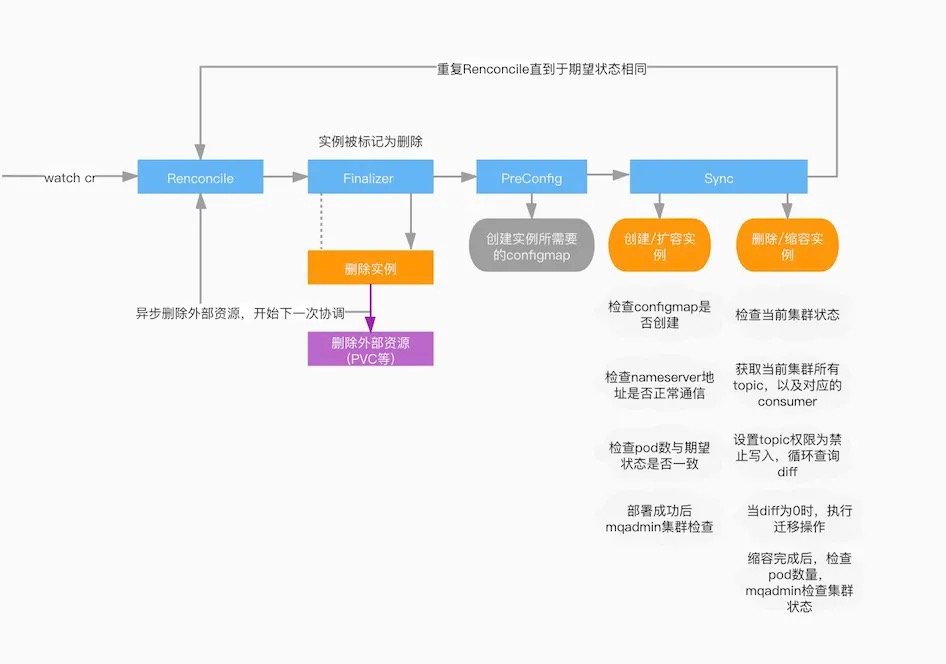
在开始一次协调循环之前,我们先看看 Operator SDK 帮助我们做了什么事:
首先它会将自定义资源的 Group 和 Version 以及 Kind(GVK)注册进 Scheme中,维持 GVK 与我们编写的自定义资源结构体的映射关系.
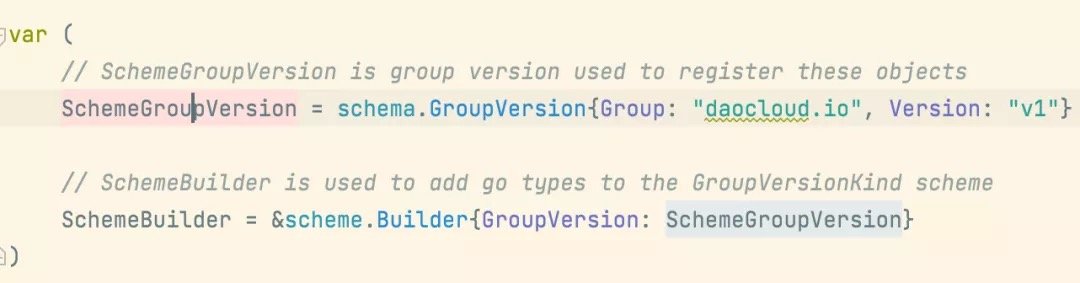
而每一个控制器中都需要 Scheme,以通过 GVK 来找到我们所要 Watch 的 Kind,也就是我们编写的自定义资源 Struct,而实例化以后便是 GVR,因此 GVK 与 GVR 便是 Reconcile 的关键,控制器又通过 Informer Watch 到自定义资源的增删改查事件,来触发 Reconcile,一次协调循环就此开始:
对比 RocketMQ 协调逻辑图,主要发生了以下几步:
Reconcile 是所有 Operator 的程序协调整个过程的入口,一般处理的逻辑是判断CR对象是新建的,修改的,还是删除的,进行一些常规处理,然后就会进入真正的协调的完整过程。
Finalize 阶段,检查实例是否需要被删除,使用 Finalize 异步删除实例所关联的外部资源例如存储等。
PreConfig 阶段,预创建实例所需要的 ConfigMap/Secret 等对象。
Sync 阶段,根据定义的 CR 编排文件,对实例进行部署以及更新操作,监控配置,存储挂载,扩容,缩容,并检查实例状态,根据实例的状态进行进一步的协调的过程,最终保障实例的状态是达到了期望的状态了。
为了保证应用完整的运维性,监控当然必不可少:
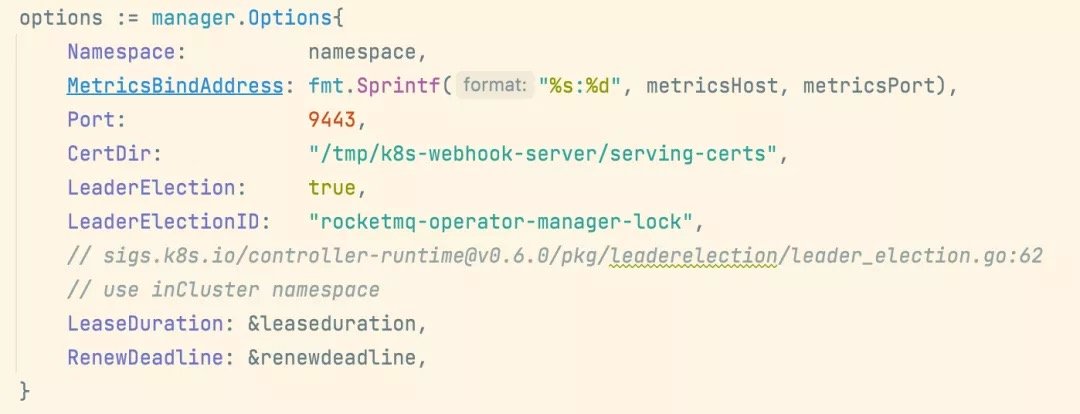
如上,通过在控制器中添加 Metrics 地址来暴露出我们的监控指标,使用 RocketMQ Exporter 提供监控指标给 Prometheus 使用
这样,一个具备自动化运维及监控,扩缩容能力的 Operator 就开发完成了,以下是它的一个基本架构:
5. Operator 社区
随着 Operator 的种类的增多和秉持着开源共享的精神,社区也相继推出了开放和共享 Operator 的机制,如 operatorhub.io, artifacthub.io。
如果大家对 Operator 实现细节感兴趣,可以参考社区中几个不错的 Operator 实现:
Kafka:CNCF 的项目,https://github.com/strimzi/strimzi-kafka-operator
ElasticSearch: ES 官方的项目,https://github.com/elastic/cloud-on-k8s
RabbitMQ: RabbitMQ 官方的项目,https://github.com/rabbitmq/cluster-operator
6. 挑战
开发一个优秀的 Operator,首先的要求是对封装组件本身需要比较熟悉。以中间件为例,来分析一下面临的挑战:
首先,对于架构师而言,应该是具备中间件架构设计能力,以及需要有中间件丰富运维经验;
其次,对于研发而言,就是有 Operator 的研发能力,以及能结合周边的监控,告警,日志,容器存储,容器网络等系统,打造完善的中间件的 Opetator 能力;
最后,对于交付而言,需要有丰富的运维经验,能理解 Operator 本身的能力,以及利用好 Operator 能力,结合客户周边的监控,告警,日志,容器存储,容器网络等系统,去完整的交付和运维 Operator,以及 Operator 负责的中间件。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!